Single Cell Analysis
This notebook depends on the ImageProcessing notebook to have been run first!
Also, be sure to run this notebook before doing the SpatialAnalysis notebook – that notebook depends on some of the outputs of this one!
[1]:
import os
import numpy as np
import pandas as pd
import palmettobug as pbug
The PalmettoBUG package is copyrighted 2024-2025 by the Medical University of South Carolina and licensed under the GPL-3 license.
It is free & open source software, can be redistributed in compliance with the GPL3 license, and comes with absolutely no warranty.
In python, use palmettobug.print_license() to see the license, or use palmettobug.print_3rd_party_license_info() to print information
about the licenses and copyright of 3rd party software used in PalmettoBUG itself or in the creation of PalmettoBUG.
[2]:
pbug.__version__
[2]:
'0.2.11'
CHANGE The following directory to match an existing directory on your computer if you are testing this tutorial on your own machine!
[3]:
my_computer_path = "C:/Users/Default/Desktop" ## CHANGE This DIRECTORY to match an existing directory on your computer if you testing this tutorial on your own machine!
Initialize Analysis class
This requires an analysis directory to have been set up previously (as in the image processing notebook)
[4]:
Analysis_directory = f"{my_computer_path}/Example_IMC/Analyses/MyAmazingAnalysis/main"
[5]:
'''
Now that the proper analysis directory structure has been made and populated with .fcs files and the metadata and panel files, we can initiate an analysis
'''
Analysis_experiment = pbug.Analysis()
Analysis_experiment.load_data(Analysis_directory)
Scaling and initial Plots
[6]:
'''
Will begin by scaling the data
'''
Analysis_experiment.do_scaling("%quantile")
[7]:
'''Batch Correction and Dropping data is also possible, but I will not do it in this noteboook (uncomment lines below to see what they do)'''
# Analysis_experiment.do_COMBAT(batch_column = "condition")
# Analysis_experiment.filter_data(to_drop = "8", column = "sample_id")
[7]:
'Batch Correction and Dropping data is also possible, but I will not do it in this noteboook (uncomment lines below to see what they do)'
[8]:
'''
Now let's look at count plots, MDS plots, and the kde histogram tracings of marker expression in each sample_id
'''
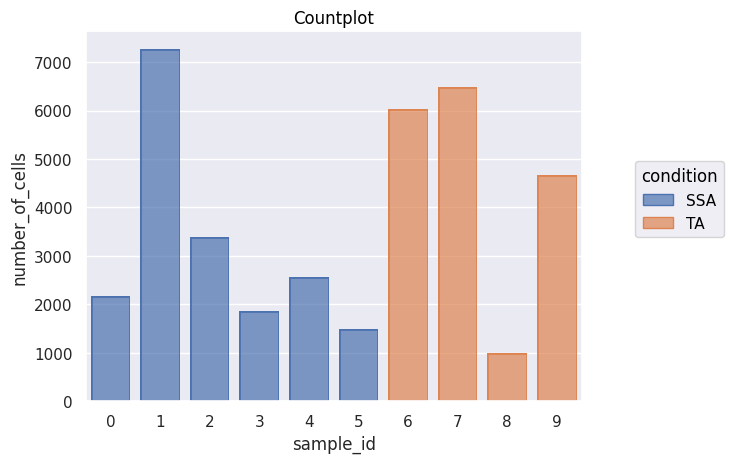
fig = Analysis_experiment.plot_cell_counts(group_by = "sample_id", color_by = "condition", filename = "countplot.png")
fig
[8]:
[9]:
'''
test_drop = Analysis_experiment.FilterData(sample_id_to_drop = 2, column = "sample_id") ### if you want to do more that one at once, you have ot make a loop and iterate (not instant convenience function
fig = Analysis_experiment.plot_cell_counts(group_by = "sample_id", color_by = "condition", filename = "countplot.png")
fig
'''
display()
[10]:
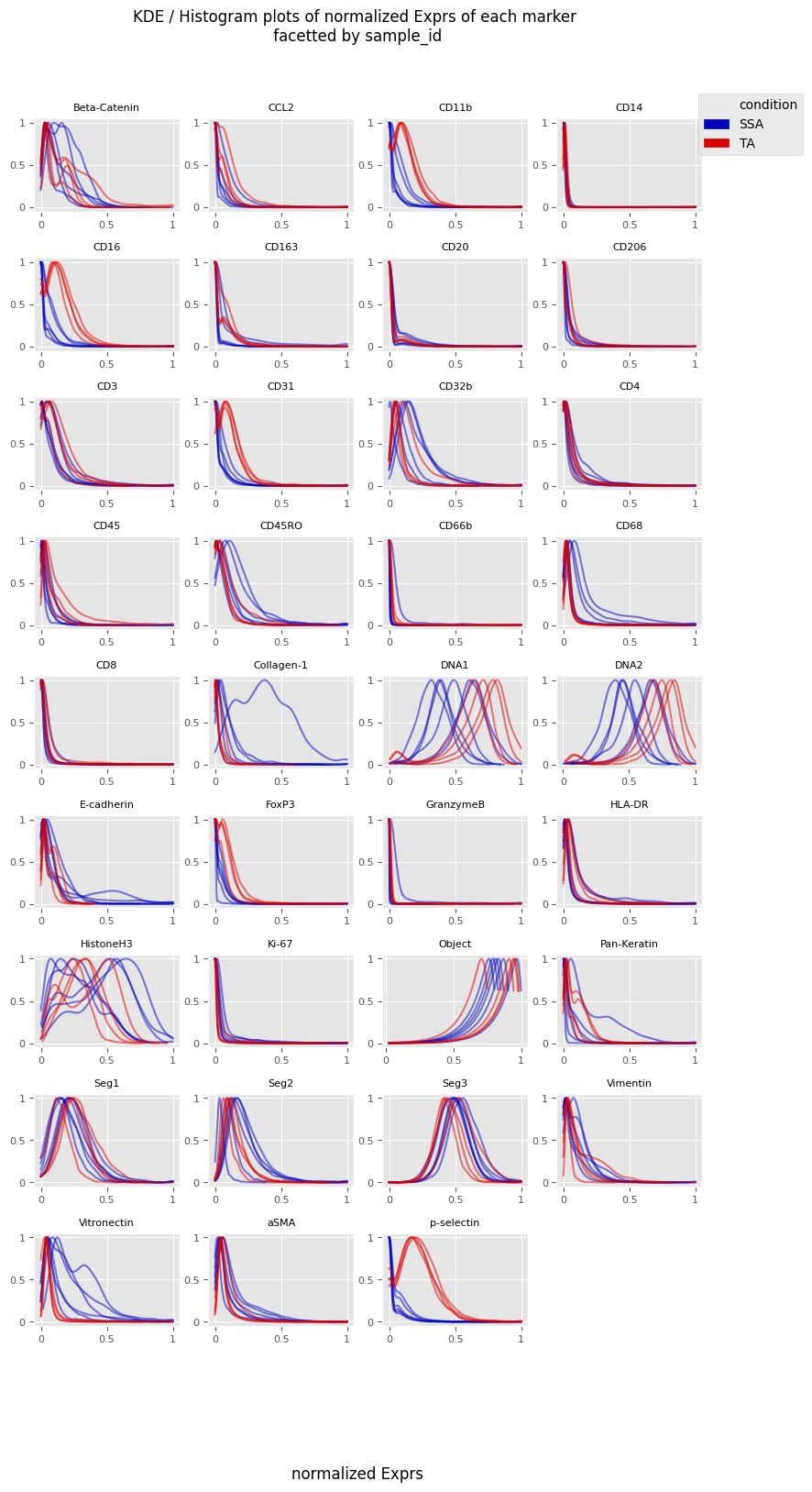
fig = Analysis_experiment.plot_ROI_histograms(filename = "sample_id_histo", color_by = "condition")
fig
[10]:
[11]:
fig = Analysis_experiment.plot_scatter(antigen1 = "Vitronectin", antigen2 = "Beta-Catenin", hue = "sample_id")
fig
[11]:
[12]:
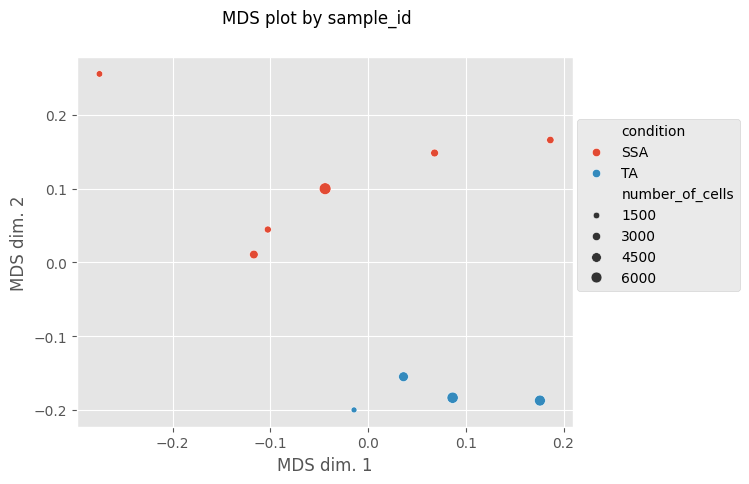
fig, MDS_df = Analysis_experiment.plot_MDS(filename = "MDS", marker_class = "type", color_by = "condition", print_stat = True)
fig
[12]:
Clustering Cells by FlowSOM & visualizing cluster characteristics
[13]:
'''
Since I don't plan on dropping any of the sample_id's I will proceed with the FlowSOM:
'''
fs = Analysis_experiment.do_flowsom(n_clusters = 20, XY_dim = 10, rlen = 50, seed = 1234)
C:\Users\benca\miniforge3\envs\main\lib\site-packages\mudata\_core\mudata.py:1531: FutureWarning: From 0.4 .update() will not pull obs/var columns from individual modalities by default anymore. Set mudata.set_options(pull_on_update=False) to adopt the new behaviour, which will become the default. Use new pull_obs/pull_var and push_obs/push_var methods for more flexibility.
self._update_attr("var", axis=0, join_common=join_common)
C:\Users\benca\miniforge3\envs\main\lib\site-packages\mudata\_core\mudata.py:1429: FutureWarning: From 0.4 .update() will not pull obs/var columns from individual modalities by default anymore. Set mudata.set_options(pull_on_update=False) to adopt the new behaviour, which will become the default. Use new pull_obs/pull_var and push_obs/push_var methods for more flexibility.
self._update_attr("obs", axis=1, join_common=join_common)
2025-10-23 10:17:26.221 | DEBUG | flowsom.main:__init__:82 - Reading input.
2025-10-23 10:17:26.245 | DEBUG | flowsom.main:__init__:84 - Fitting model: clustering and metaclustering.
2025-10-23 10:17:57.586 | DEBUG | flowsom.main:__init__:86 - Updating derived values.
[14]:
# svg_fig_path = Analysis_experiment.plot_facetted_heatmap(filename = "facetted_heatmap", subsetting_column = "sample_id", groupby_column = "metaclustering", marker_class = "type", number_of_columns = 3, analysis_anndata = None)
[15]:
'''
Now, will plot various ways of examining the clustering we've created:
'''
fig = Analysis_experiment.plot_medians_heatmap(filename = "heatmap_metaclustering", marker_class = "type", groupby = "metaclustering", figsize = (8,8))
fig
[15]:
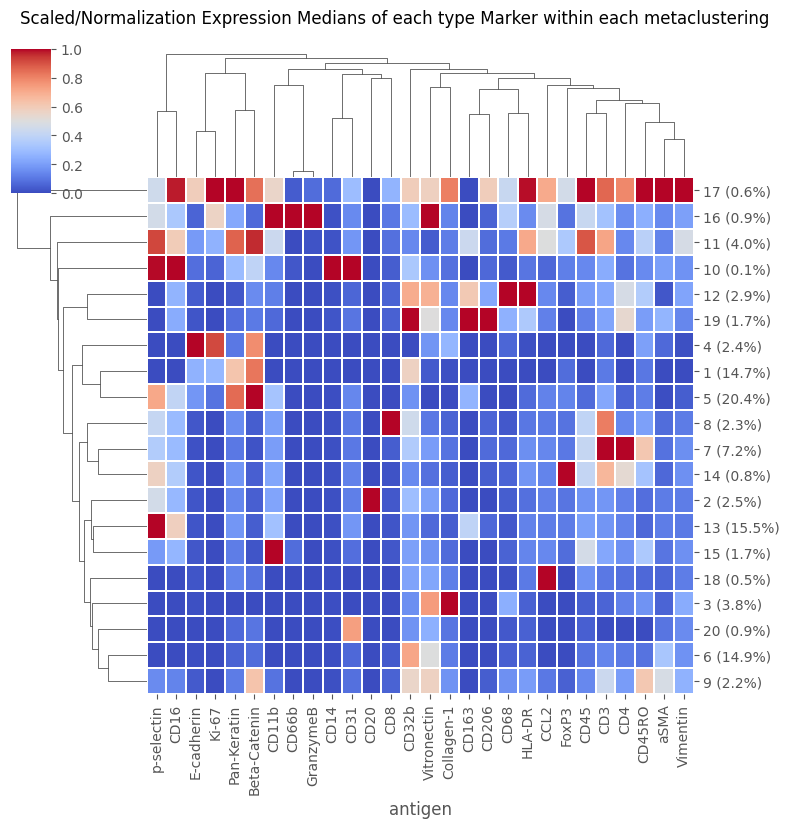
[16]:
fig = Analysis_experiment.plot_cluster_histograms(filename = "vimentin_kde_by_cluster", groupby_column = 'metaclustering', antigen = "Vimentin")
fig
[16]:
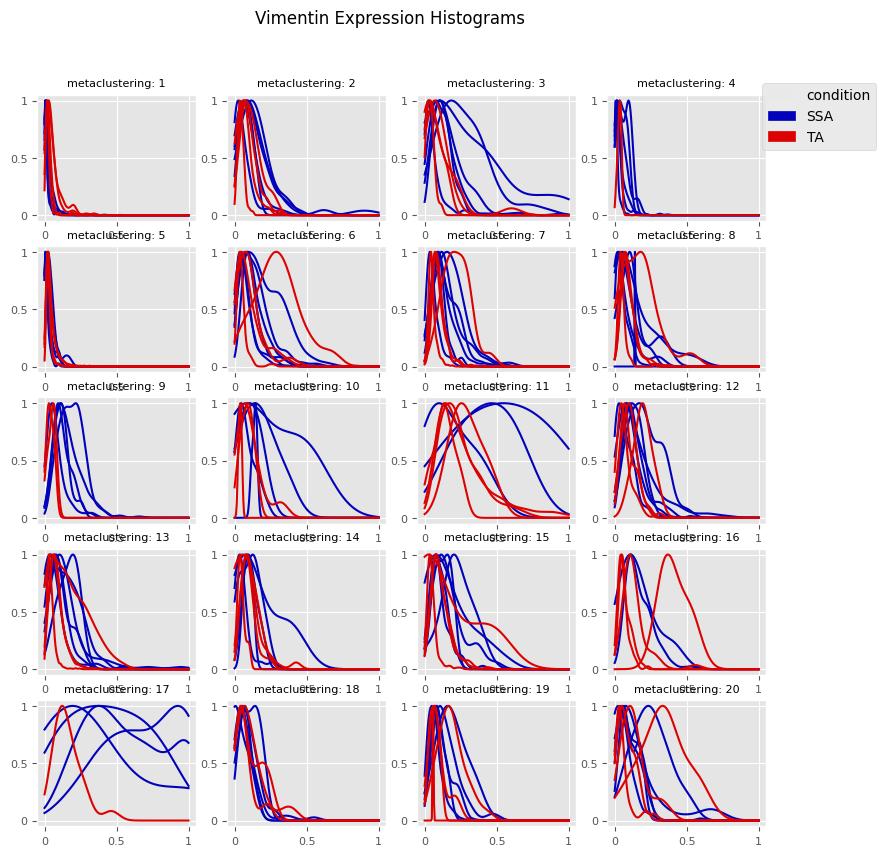
[17]:
fig = Analysis_experiment.plot_cluster_distributions(filename = "cluster_expression", groupby_column = "metaclustering", marker_class = 'type',
plot_type = "violin", comp_type = "raw")
fig
[17]:
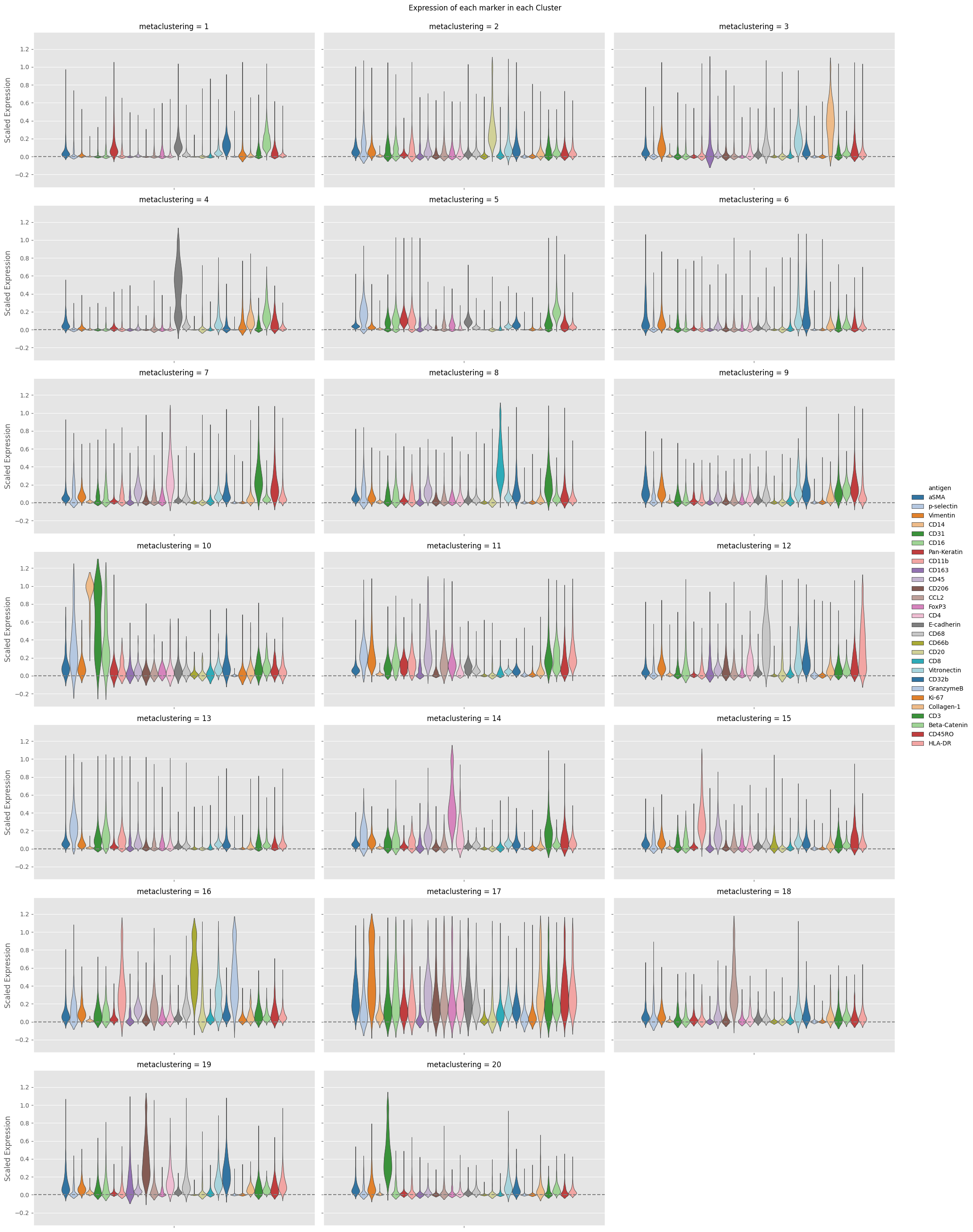
Cluster comparison Statistics
[18]:
stats_out = Analysis_experiment.do_cluster_stats(groupby_column = "metaclustering", marker_class = 'type')
cluster_to_examine = 2
display(stats_out[cluster_to_examine]) ## or display(Analysis_experiment.df_out_dict[cluster_to_examine])
fig = Analysis_experiment.plot_cluster_stats(filename = "cluster_stat_heatmap", statistic = "FDR_corrected")
fig
| F_statistic | p_values | FDR_corrected | Difference in expression mean | st_error | |
|---|---|---|---|---|---|
| CD20 | 551.300000 | 1.165000e-57 | 2.800000e-24 | 0.388500 | 0.051750 |
| Vitronectin | 6.484000 | 1.169000e-02 | 1.636000e-01 | 0.082550 | 0.047490 |
| CD3 | 2.577000 | 1.101000e-01 | 6.540000e-01 | -0.046660 | 0.008324 |
| Beta-Catenin | 2.359000 | 1.263000e-01 | 6.540000e-01 | -0.034550 | 0.008823 |
| CD45RO | 2.072000 | 1.517000e-01 | 6.540000e-01 | -0.042090 | 0.011080 |
| CD4 | 1.400000 | 2.383000e-01 | 6.540000e-01 | -0.031370 | 0.004721 |
| Pan-Keratin | 1.338000 | 2.488000e-01 | 6.540000e-01 | -0.026900 | 0.006542 |
| E-cadherin | 1.317000 | 2.526000e-01 | 6.540000e-01 | -0.033910 | 0.006881 |
| HLA-DR | 1.208000 | 2.732000e-01 | 6.540000e-01 | -0.031710 | 0.008501 |
| CD45 | 1.030000 | 3.114000e-01 | 6.540000e-01 | -0.025370 | 0.009934 |
| CD31 | 0.886300 | 3.477000e-01 | 6.540000e-01 | -0.052630 | 0.012650 |
| FoxP3 | 0.860200 | 3.549000e-01 | 6.540000e-01 | -0.031020 | 0.008054 |
| CD16 | 0.850600 | 3.576000e-01 | 6.540000e-01 | -0.034360 | 0.016420 |
| Ki-67 | 0.814600 | 3.679000e-01 | 6.540000e-01 | -0.015410 | 0.001881 |
| CD206 | 0.753500 | 3.865000e-01 | 6.540000e-01 | -0.024240 | 0.005090 |
| Vimentin | 0.681800 | 4.100000e-01 | 6.540000e-01 | -0.026890 | 0.010230 |
| CD14 | 0.671200 | 4.137000e-01 | 6.540000e-01 | -0.054860 | 0.001081 |
| CD11b | 0.611600 | 4.352000e-01 | 6.540000e-01 | -0.030840 | 0.013640 |
| CCL2 | 0.589100 | 4.438000e-01 | 6.540000e-01 | -0.025260 | 0.012680 |
| GranzymeB | 0.440100 | 5.079000e-01 | 7.069000e-01 | -0.025280 | 0.003519 |
| CD66b | 0.395600 | 5.302000e-01 | 7.069000e-01 | -0.025550 | 0.004459 |
| CD8 | 0.281400 | 5.964000e-01 | 7.339000e-01 | -0.019500 | 0.007146 |
| CD68 | 0.271600 | 6.029000e-01 | 7.339000e-01 | -0.015710 | 0.019620 |
| Collagen-1 | 0.176700 | 6.747000e-01 | 7.635000e-01 | 0.014100 | 0.038710 |
| CD163 | 0.168800 | 6.817000e-01 | 7.635000e-01 | -0.009545 | 0.013080 |
| aSMA | 0.111500 | 7.388000e-01 | 7.711000e-01 | -0.006941 | 0.008102 |
| p-selectin | 0.107300 | 7.436000e-01 | 7.711000e-01 | -0.013250 | 0.024270 |
| CD32b | 0.000938 | 9.756000e-01 | 9.756000e-01 | 0.000701 | 0.015340 |
[18]:
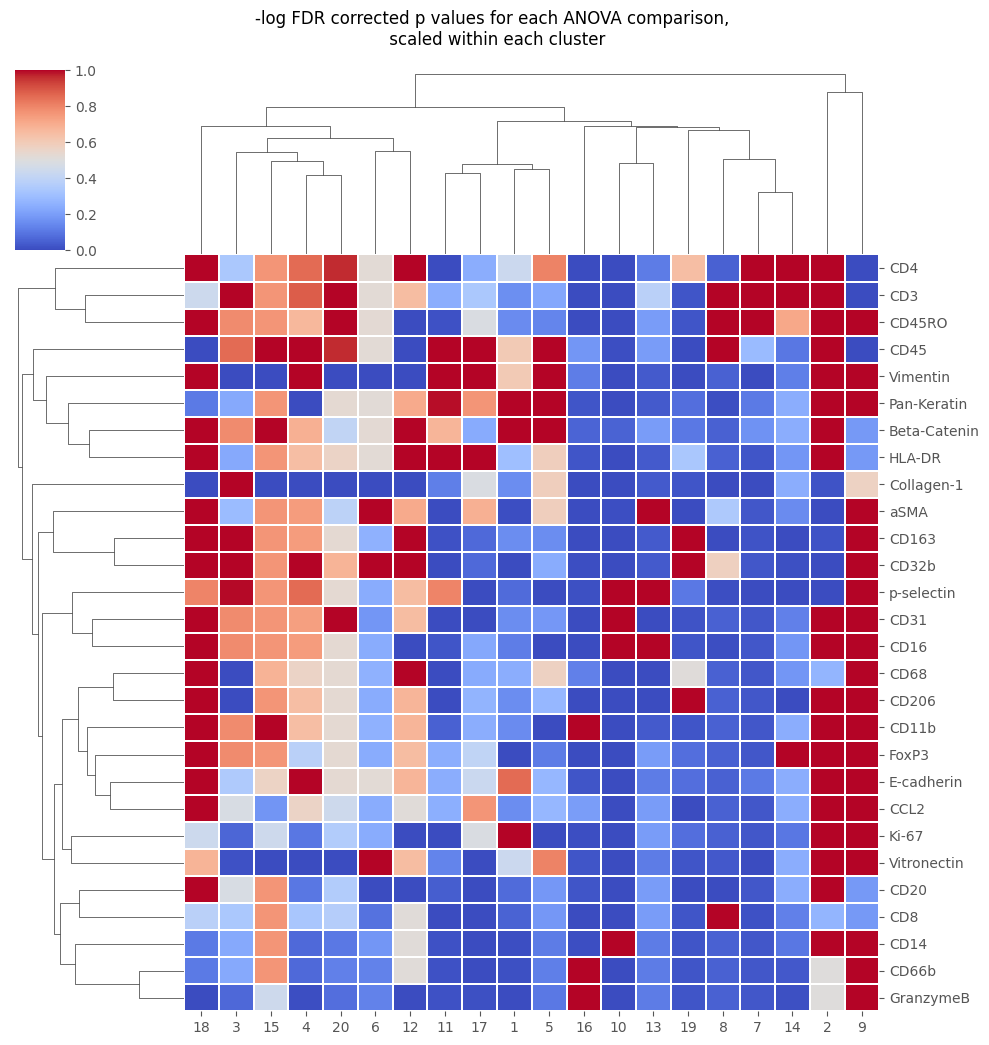
[19]:
'''While the functions that do cluster comparison are only used for cell groupings in the GUI, it is also possible to do the same cluster comparison using any other grouping of the data --
including condition:
'''
stats_out = Analysis_experiment.do_cluster_stats(groupby_column = "condition", marker_class = 'type') ## can also perform the same calculation using treatment condition as the comparator instead of clusters
display(stats_out['SSA'])
| F_statistic | p_values | FDR_corrected | Difference in expression mean | st_error | |
|---|---|---|---|---|---|
| p-selectin | 385.100000 | 4.729000e-08 | 0.000001 | -0.168100 | 0.005314 |
| CD16 | 41.590000 | 1.986000e-04 | 0.002780 | -0.090070 | 0.009307 |
| CD11b | 31.530000 | 5.016000e-04 | 0.003882 | -0.072950 | 0.009510 |
| CD31 | 30.570000 | 5.546000e-04 | 0.003882 | -0.057250 | 0.006950 |
| FoxP3 | 14.140000 | 5.537000e-03 | 0.031010 | -0.042930 | 0.006364 |
| Vitronectin | 9.155000 | 1.642000e-02 | 0.076610 | 0.110000 | 0.028950 |
| CD45 | 4.378000 | 6.975000e-02 | 0.279000 | -0.042980 | 0.007915 |
| E-cadherin | 3.709000 | 9.030000e-02 | 0.316100 | 0.047020 | 0.018600 |
| CD68 | 3.294000 | 1.071000e-01 | 0.333200 | 0.059020 | 0.025920 |
| CD45RO | 2.305000 | 1.675000e-01 | 0.448200 | 0.041670 | 0.020200 |
| Ki-67 | 2.177000 | 1.783000e-01 | 0.448200 | 0.018270 | 0.009101 |
| aSMA | 2.030000 | 1.921000e-01 | 0.448200 | 0.029240 | 0.015360 |
| Collagen-1 | 1.650000 | 2.348000e-01 | 0.490500 | 0.087260 | 0.054250 |
| CCL2 | 1.572000 | 2.453000e-01 | 0.490500 | -0.021590 | 0.010100 |
| CD32b | 1.286000 | 2.895000e-01 | 0.540500 | 0.047690 | 0.029910 |
| CD163 | 1.113000 | 3.222000e-01 | 0.563900 | -0.020270 | 0.015230 |
| CD14 | 1.000000 | 3.465000e-01 | 0.570700 | -0.002291 | 0.001498 |
| CD3 | 0.899700 | 3.706000e-01 | 0.576500 | -0.018690 | 0.011890 |
| CD8 | 0.735100 | 4.162000e-01 | 0.613300 | -0.008602 | 0.005750 |
| GranzymeB | 0.189800 | 6.746000e-01 | 0.907100 | 0.005425 | 0.009935 |
| CD20 | 0.142500 | 7.156000e-01 | 0.907100 | 0.004182 | 0.008791 |
| Vimentin | 0.107700 | 7.512000e-01 | 0.907100 | 0.006222 | 0.007905 |
| CD206 | 0.080280 | 7.841000e-01 | 0.907100 | -0.003491 | 0.008396 |
| CD4 | 0.061830 | 8.099000e-01 | 0.907100 | 0.003861 | 0.011470 |
| Pan-Keratin | 0.047800 | 8.324000e-01 | 0.907100 | -0.008437 | 0.028910 |
| Beta-Catenin | 0.042230 | 8.423000e-01 | 0.907100 | -0.006414 | 0.017690 |
| HLA-DR | 0.007017 | 9.353000e-01 | 0.969900 | -0.002186 | 0.018020 |
| CD66b | 0.001047 | 9.750000e-01 | 0.975000 | -0.000394 | 0.009449 |
Dimensionality Reduction: UMAP and PCA
These can assist in performing a merging / annotation, but also can be performed after merging as well.
[20]:
'''
Generating UMAP and PCA plots:
'''
Analysis_experiment.do_UMAP(marker_class = "type", cell_number = 1000, seed = 0)
C:\Users\benca\miniforge3\envs\main\lib\site-packages\tqdm\auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
[21]:
Analysis_experiment.plot_UMAP(filename = "umap", color_by = 'metaclustering', palette = None, legend_loc = 'on data', legend_fontsize = 6)
[21]:

[22]:
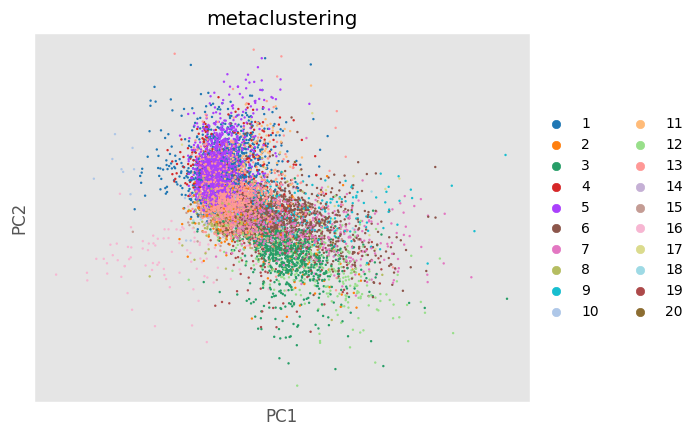
Analysis_experiment.do_PCA(marker_class = "type", cell_number = 1000, seed = 0)
fig = Analysis_experiment.plot_PCA(filename = "pca", color_by = 'metaclustering', palette = None)
fig
[22]:
[23]:
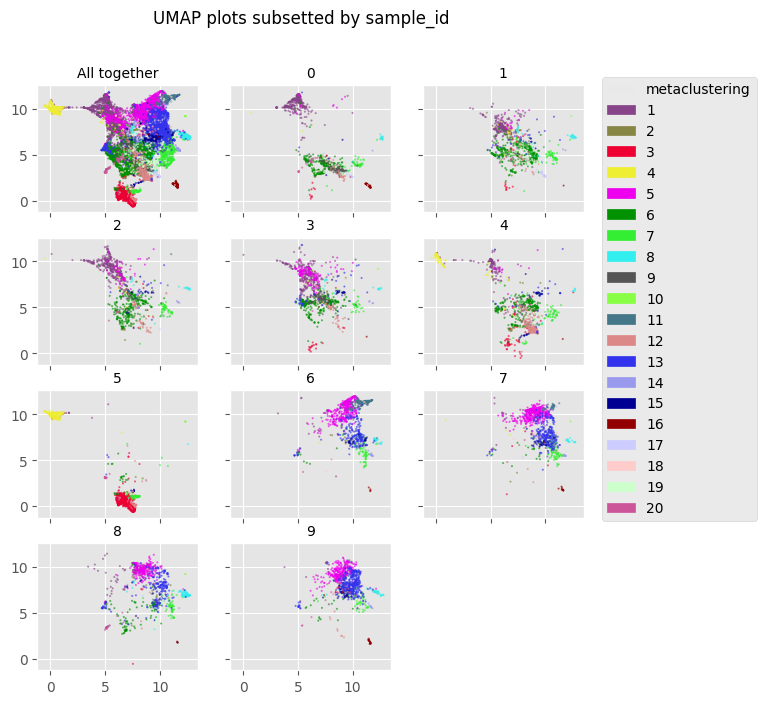
fig = Analysis_experiment.plot_facetted_DR(filename = "facetted_umap", color_by = "metaclustering", subsetting_column = "sample_id",
number_of_columns = 3, color_bank = None, kind = "UMAP")
fig
[23]:
Cluster Merging and Annotation
[24]:
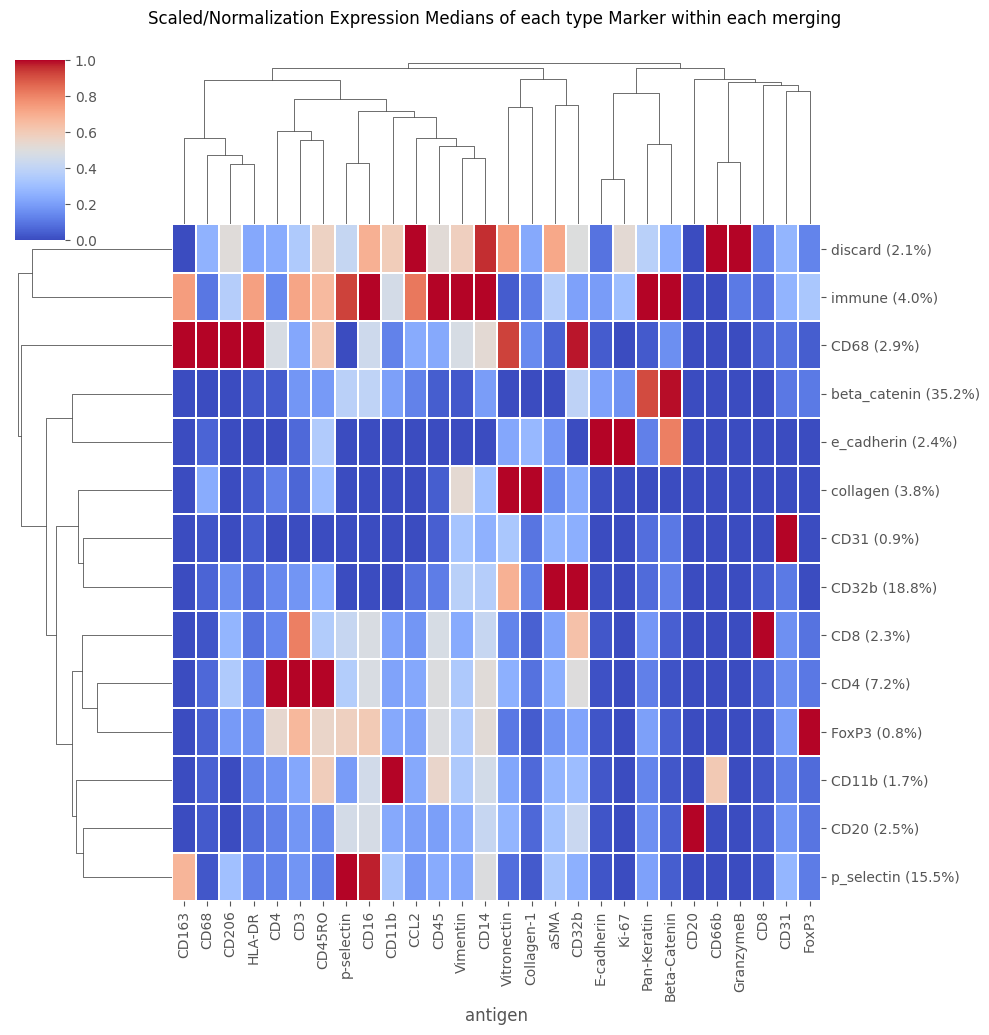
'''
Now we can do a cluster merging
This requires setting up a table where we manually annotate the biological labels of each of the numbered metaclusters
'''
#manual_annotations = ['e_cadherin', 'vitronectin', 'CD68', 'beta_catenin', 'beta_catenin', 'beta_catenin', 'beta_catenin', 'collagen', 'CD32b', 'Cd11b',
# 'CD8', 'CD4', 'aSMA', 'CD31', 'beta_catenin', 'CD31', 'discard', 'FoxP3', 'p_selectin', 'discard']
manual_annotations = ['beta_catenin', 'CD20', 'collagen', 'e_cadherin', 'beta_catenin', 'CD32b', 'CD4', 'CD8', 'CD32b', 'discard',
'immune', 'CD68', 'p_selectin', 'FoxP3', 'CD11b', 'discard', 'discard', 'discard', 'CD32b', 'CD31']
merging_table = pd.DataFrame()
merging_table['original_cluster'] = Analysis_experiment.data.obs['metaclustering'].astype('int').sort_values().unique()
merging_table['new_cluster'] = manual_annotations
mergings_sub_folder = Analysis_experiment.directory + "/mergings"
if not os.path.exists(mergings_sub_folder):
os.mkdir(mergings_sub_folder)
merging_table.to_csv(mergings_sub_folder + "/merging.csv", index = False)
Analysis_experiment.do_cluster_merging(mergings_sub_folder + "/merging.csv")
fig = Analysis_experiment.plot_medians_heatmap(filename = "heatmap_merging", marker_class = "type", groupby = "merging")
fig
[24]:
[25]:
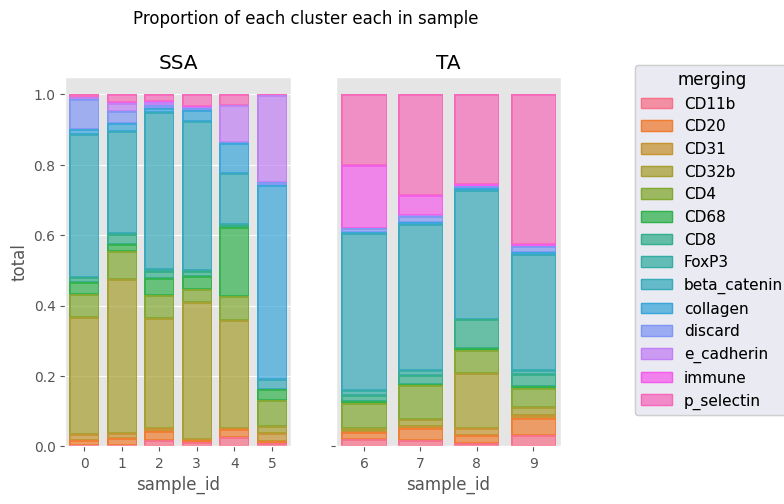
fig = Analysis_experiment.plot_cluster_abundance_1(filename = "abundance_boxplot", groupby_column = "merging") #, hue = "condition", plot_type = "boxplot")
fig
C:\Users\benca\miniforge3\envs\main\lib\site-packages\seaborn\_core\plot.py:1406: FutureWarning: Setting an item of incompatible dtype is deprecated and will raise an error in a future version of pandas. Value '[0.004593477262287551 0.013780431786862656 0.018373909049150206
0.33210840606339 0.06522737712448323 0.034451079467156635
0.011483693155718878 0.0022967386311437757 0.4042259990813045
0.015617822691777675 0.08589802480477722 0.0036747818098300414
0.00045934772622875517 0.0078089113458888375 0.0035758492642002475
0.021042497593178378 0.01347820107275478 0.4383166001925457
0.07949387979645166 0.019942236281116764 0.028744326777609682
0.0030257186081694403 0.28991885572823545 0.022417824233255397
0.032045110713794525 0.02489341218539403 0.00027506532801540364
0.022830422225278504 0.01768346595932803 0.02564102564102564
0.008841732979664015 0.3132920719127616 0.06395520188623637
0.04774535809018567 0.022104332449160036 0.00618921308576481
0.4438549955791335 0.011494252873563218 0.00825228411435308
0.010610079575596816 0.0011788977306218685 0.019157088122605363
0.01242571582928147 0.007023230686115613 0.002701242571582928
0.3878984332793085 0.037817396002161 0.03511615343057806
0.014586709886547812 0.0037817396002160996 0.42301458670988656
0.03079416531604538 0.005402485143165856 0.0037817396002160996
0.0016207455429497568 0.03403565640194489 0.02612085769980507
0.022612085769980507 0.0050682261208577 0.3048732943469786
0.07017543859649122 0.19454191033138402 0.005847953216374269
0.0023391812865497076 0.14541910331384014 0.08382066276803118
0.004678362573099415 0.10526315789473684 0.029239766081871343
0.010745466756212223 0.004029550033579583 0.02216252518468771
0.020819341840161182 0.0745466756212223 0.03089321692411014
0.001343183344526528 0.026192075218267292 0.5507051712558765
0.010073875083948958 0.2458025520483546 0.002686366689053056]' has dtype incompatible with float64, please explicitly cast to a compatible dtype first.
new_series.loc[idx] = view_scale(layer_df.loc[idx, var])
C:\Users\benca\miniforge3\envs\main\lib\site-packages\seaborn\_core\plot.py:1406: FutureWarning: Setting an item of incompatible dtype is deprecated and will raise an error in a future version of pandas. Value '[0.02087821043910522 0.019221209610604806 0.0036454018227009112
0.00811930405965203 0.07174813587406793 0.004142502071251036
0.01888980944490472 0.01507870753935377 0.44540182270091133
0.001491300745650373 0.01275890637945319 0.00016570008285004143
0.1768019884009942 0.2016570008285004 0.0188039457459926
0.03252157829839704 0.005548705302096177 0.020499383477188656
0.0967940813810111 0.0038532675709001232 0.02404438964241677
0.014642416769420468 0.4166152897657213 0.0032367447595561035
0.018649815043156596 0.0012330456226880395 0.05687422934648582
0.28668310727496915 0.009109311740890687 0.02327935222672065
0.019230769230769232 0.15789473684210525 0.06376518218623482
0.006072874493927126 0.08198380566801619 0.0020242914979757085
0.36538461538461536 0.005060728744939271 0.00708502024291498
0.004048582995951417 0.2550607287449393 0.033190578158458245
0.048179871520342615 0.008993576017130621 0.022055674518201285
0.052248394004282654 0.008137044967880086 0.034261241970021415
0.009635974304068522 0.32955032119914346 0.0053533190578158455
0.01841541755888651 0.00021413276231263382 0.004282655246252677
0.4254817987152034]' has dtype incompatible with float64, please explicitly cast to a compatible dtype first.
new_series.loc[idx] = view_scale(layer_df.loc[idx, var])
[25]:
[26]:
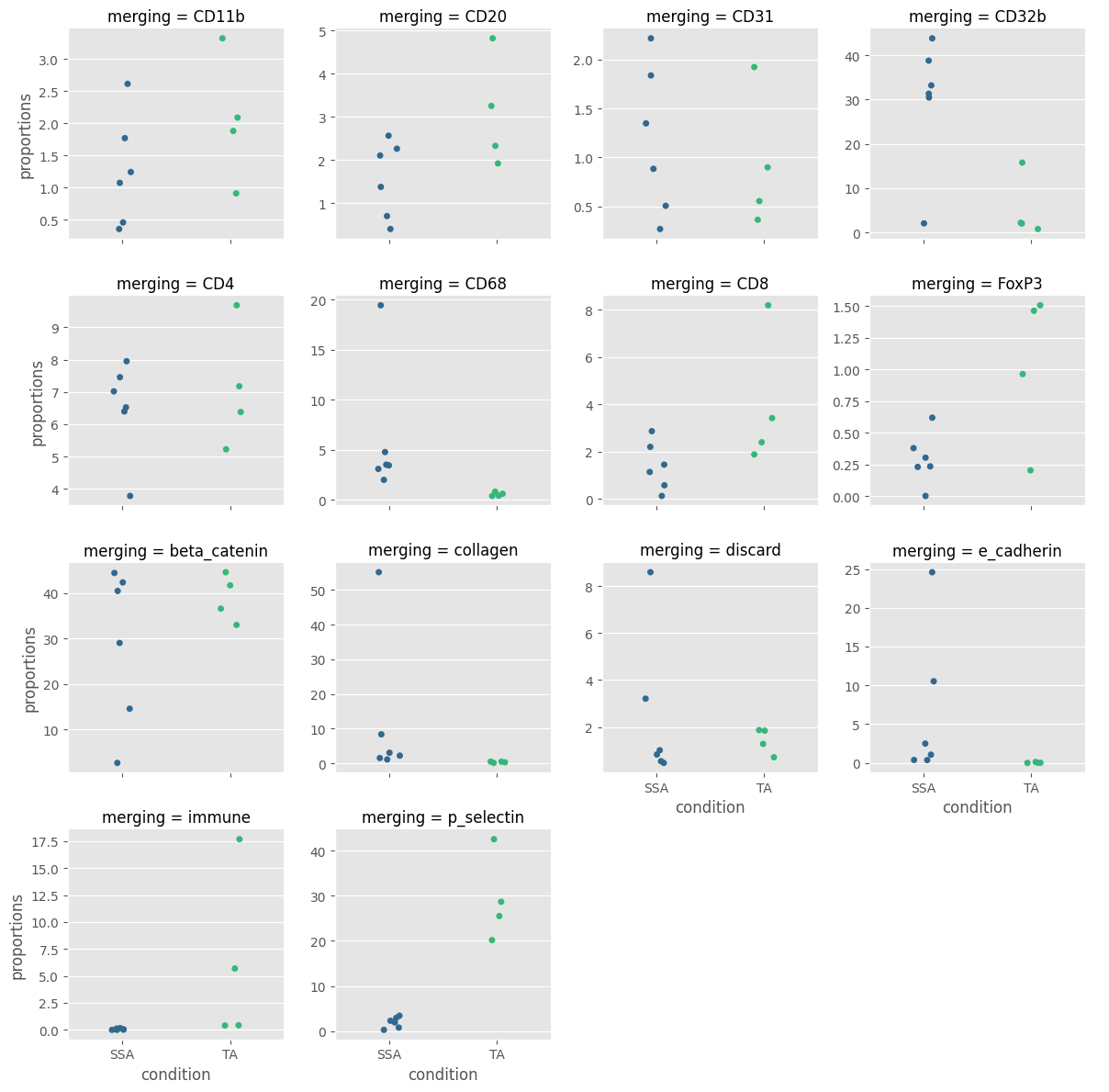
fig = Analysis_experiment.plot_cluster_abundance_2(filename = "abundance_boxplot", groupby_column = "merging", hue = "condition", plot_type = "stripplot")
fig
[26]:
Doing Statistics
[27]:
GLM_result_table = Analysis_experiment.do_count_GLM(variable = "condition", conditions = ["SSA","TA"],
groupby_column = "metaclustering", family = "Poisson", filename = "GLM_stats")
GLM_result_table
[27]:
| comparison | metaclustering | pvalue | p_adj | SSA est. avg | SSA 95% CI +/- | TA est. avg | TA 95% CI +/- | |
|---|---|---|---|---|---|---|---|---|
| 1 | SSA vs. TA | metaclustering1 | 0.0 | 2.000000e-25 | 26.9 | 0.379 | 2.21 | 0.115 |
| 2 | SSA vs. TA | metaclustering6 | 0.0 | 2.000000e-25 | 27.3 | 0.381 | 2.11 | 0.112 |
| 16 | SSA vs. TA | metaclustering13 | 0.0 | 2.000000e-25 | 2.08 | 0.105 | 29.2 | 1.53 |
| 7 | SSA vs. TA | metaclustering5 | 0.0 | 2.000000e-25 | 3.47 | 0.136 | 37.9 | 1.55 |
| 12 | SSA vs. TA | metaclustering3 | 2.07e-119 | 2.000000e-25 | 7.08 | 0.194 | 0.33 | 0.0437 |
| 10 | SSA vs. TA | metaclustering12 | 5.1e-103 | 2.000000e-25 | 5.29 | 0.168 | 0.517 | 0.0559 |
| 11 | SSA vs. TA | metaclustering19 | 5.58e-61 | 2.000000e-25 | 3.13 | 0.129 | 0.264 | 0.0398 |
| 19 | SSA vs. TA | metaclustering11 | 3e-56 | 2.000000e-25 | 0.0533 | 0.0172 | 8.03 | 2.59 |
| 15 | SSA vs. TA | metaclustering4 | 3.69e-44 | 2.000000e-25 | 4.63 | 0.157 | 0.055 | 0.0178 |
| 9 | SSA vs. TA | metaclustering9 | 1.21e-42 | 2.000000e-25 | 4.28 | 0.151 | 0.055 | 0.0178 |
| 14 | SSA vs. TA | metaclustering17 | 3.52e-22 | 6.400000e-22 | 1.07 | 0.0755 | 0.127 | 0.0281 |
| 17 | SSA vs. TA | metaclustering14 | 1.56e-21 | 2.600000e-21 | 0.325 | 0.0418 | 1.28 | 0.185 |
| 8 | SSA vs. TA | metaclustering15 | 4.95e-18 | 7.620000e-18 | 1.08 | 0.0759 | 2.27 | 0.195 |
| 5 | SSA vs. TA | metaclustering2 | 3.28e-15 | 4.690000e-15 | 1.85 | 0.0994 | 3.16 | 0.215 |
| 6 | SSA vs. TA | metaclustering8 | 7.17e-09 | 9.560000e-09 | 1.88 | 0.1 | 2.81 | 0.195 |
| 13 | SSA vs. TA | metaclustering20 | 3.63e-07 | 4.540000e-07 | 1.17 | 0.079 | 0.655 | 0.0747 |
| 0 | SSA vs. TA | metaclustering18 | 0.0239 | 2.810000e-02 | 0.533 | 0.0534 | 0.374 | 0.059 |
| 3 | SSA vs. TA | metaclustering7 | 0.0319 | 3.540000e-02 | 6.92 | 0.192 | 7.52 | 0.292 |
| 4 | SSA vs. TA | metaclustering16 | 0.0995 | 1.050000e-01 | 0.822 | 0.0663 | 0.985 | 0.108 |
| 18 | SSA vs. TA | metaclustering10 | 0.204 | 2.040000e-01 | 0.165 | 0.0299 | 0.116 | 0.0331 |
[28]:
variable = 'condition'
conditions = list(Analysis_experiment.data.obs[variable].unique()) #### if all conditions are going to be looked at, as in this example, you can pass in and empty list instead
ouput_df = Analysis_experiment.do_abundance_ANOVAs(groupby_column = 'metaclustering', conditions = conditions)
ouput_df
[28]:
| f statistics | p_value | p_adj | SSA mean % | SSA stdev | TA mean % | TA stdev | |
|---|---|---|---|---|---|---|---|
| 13 | 50.88000 | 0.000099 | 0.001135 | 1.9290 | 1.21400 | 29.22000 | 9.55200 |
| 5 | 48.89000 | 0.000113 | 0.001135 | 4.2140 | 6.04900 | 34.87000 | 7.87800 |
| 6 | 8.78600 | 0.018030 | 0.105500 | 22.8600 | 11.35000 | 4.39400 | 5.80100 |
| 14 | 8.02200 | 0.022070 | 0.105500 | 0.2939 | 0.20340 | 1.03500 | 0.60720 |
| 1 | 7.38100 | 0.026380 | 0.105500 | 24.6600 | 14.39000 | 4.05100 | 4.79900 |
| 2 | 4.94900 | 0.056760 | 0.184000 | 1.5690 | 0.88350 | 3.08000 | 1.28500 |
| 9 | 4.46300 | 0.067600 | 0.184000 | 5.2570 | 4.81300 | 0.06777 | 0.04377 |
| 8 | 4.23500 | 0.073590 | 0.184000 | 1.4020 | 1.01600 | 3.97900 | 2.88400 |
| 11 | 3.46500 | 0.099700 | 0.221600 | 0.0589 | 0.06666 | 6.05000 | 8.14200 |
| 12 | 2.63200 | 0.143400 | 0.286800 | 6.0450 | 6.62900 | 0.55510 | 0.19850 |
| 15 | 1.87300 | 0.208400 | 0.368100 | 1.2520 | 0.84570 | 2.05000 | 0.98960 |
| 4 | 1.76300 | 0.220800 | 0.368100 | 6.5670 | 9.63200 | 0.04032 | 0.05608 |
| 17 | 1.49400 | 0.256400 | 0.394500 | 0.6740 | 0.89490 | 0.11190 | 0.13660 |
| 3 | 1.12600 | 0.319700 | 0.456700 | 11.9100 | 21.31000 | 0.37860 | 0.17930 |
| 18 | 0.85390 | 0.382500 | 0.510000 | 0.4485 | 0.29510 | 0.28480 | 0.23600 |
| 19 | 0.69360 | 0.429100 | 0.536400 | 1.8430 | 2.37500 | 0.75250 | 1.25400 |
| 7 | 0.31650 | 0.589100 | 0.693100 | 6.5200 | 1.46100 | 7.11400 | 1.88800 |
| 20 | 0.25770 | 0.625400 | 0.694900 | 1.1770 | 0.76190 | 0.93550 | 0.69460 |
| 10 | 0.12290 | 0.735000 | 0.773700 | 0.1751 | 0.11610 | 0.14850 | 0.11980 |
| 16 | 0.03571 | 0.854800 | 0.854800 | 1.1420 | 2.70400 | 0.87760 | 0.55680 |
[29]:
ouptut_df = Analysis_experiment.do_state_exprs_ANOVAs( filename = "state_exprs_ANOVA_table",
marker_class = "none",
groupby_column = 'metaclustering',
variable = 'condition',
statistic = 'mean')
[30]:
ouptut_df
[30]:
| antigen | metaclustering | p_value | p_adj | F statistic | avg SSA mean exprs | SSA avg stdev | avg TA mean exprs | TA avg stdev | |
|---|---|---|---|---|---|---|---|---|---|
| 122 | Seg3 | 3 | 0.00891 | 0.1983 | 11.790000 | 0.3392 | 0.26840 | 0.4799 | 0.04512 |
| 4 | DNA1 | 5 | 0.01171 | 0.1983 | 10.560000 | 0.4320 | 0.11270 | 0.6380 | 0.08775 |
| 7 | DNA1 | 8 | 0.01291 | 0.1983 | 10.140000 | 0.3133 | 0.26080 | 0.6831 | 0.17120 |
| 127 | Seg3 | 8 | 0.01425 | 0.1983 | 9.730000 | 0.3006 | 0.25650 | 0.4493 | 0.05539 |
| 27 | DNA2 | 8 | 0.01473 | 0.1983 | 9.593000 | 0.3503 | 0.28560 | 0.7206 | 0.15490 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 86 | Seg1 | 7 | 0.96940 | 0.9970 | 0.001569 | 0.2344 | 0.05965 | 0.1815 | 0.04308 |
| 111 | Seg2 | 12 | 0.97860 | 0.9970 | 0.000764 | 0.1760 | 0.08552 | 0.1592 | 0.03671 |
| 87 | Seg1 | 8 | 0.99040 | 0.9970 | 0.000154 | 0.1760 | 0.14860 | 0.2117 | 0.09686 |
| 108 | Seg2 | 9 | 0.99620 | 0.9970 | 0.000024 | 0.3037 | 0.17850 | 0.1106 | 0.04424 |
| 62 | Object | 3 | 0.99700 | 0.9970 | 0.000015 | 0.4936 | 0.38310 | 0.7909 | 0.19140 |
140 rows × 9 columns
Exporting: Saving and Reloading Cell Clsuterings / Annotations
[31]:
'''
We can export a clustering -- it can be reloaded into the same Analysis later, so we don't have to re-do our clustering algorithm
'''
save_type_options = ["metaclustering","merging","classification","leiden"] ## these are the options naturally produced by PalmettoBUG
## and index with this command:
export, path = Analysis_experiment.export_clustering(groupby_column = "merging", identifier = "")
[32]:
'''
Reloading an exported clustering is easy:
Note that if the condition, patient_id columns in self.data.obs or the data itself (self.data.X) have changed since when the clustering was first loaded
a caution message will be printed (while still adding the clustering). These messages are to alert you that the state of these columns / the data
does not match the state of those columns / the data when you originally saved the clustering. This can happen, for example, if you scaled the data before
clustering and then later reopened the Analysis & forgot to scale the data again before reloading the clustering.
These caution messages, even though they don't block the reloading of the cell clustering, are meant to alert you to unusual changes in the data and
give you a chance to fix problems / mistakes if those changes were unintentional.
'''
Analysis_experiment.load_clustering(path = Analysis_experiment.clusterings_dir + "/merging.csv")
Exporting the entire Single Cell Data as a CSV
First, export the entire dataset to a CSV file.
The data is what is currently inside the PalmettoBUG Analysis object (effectively, self.data.X + self.data.obs). If the include_marker_class_row parameter is set to True (which should ONLY be the case if you intend to reload the CSV into PalmettoBUG), then the marker_class of each channel (type/state/none, etc. from self.data.var) will be included as numbers in the last row of the CSV.
NOTE: what is exported is the CURRENT state of the data – it will reflect any changes made to the data like scaling, batch correction, or dropping a sample.
When a filename is specified, as in these examples, a CSV file is automatically written to the expected PalmettoBUG location on the disk. However, if filename is left as the default value of None, then only the pandas dataframe will be returned – allowing the user to do further calculations in Python before exporting with pd.to_csv().
[33]:
full_data_export = Analysis_experiment.export_data(filename = "CSVforReload", include_marker_class_row = False)
## Note: the include_marker_class_row parameter should be True ONLY if you intend on reloading the data into PalmettoBUG itself (say from one installation of PalmettoBUG to another,
## It includes a row at the bottom of the data giving the marker_class (type / state/ none, etc.) of each channel
full_data_export
[33]:
| antigen | Object | aSMA | p-selectin | Vimentin | CD14 | CD31 | CD16 | Pan-Keratin | CD11b | CD163 | ... | index | sample_id | file_name | patient_id | condition | clustering | metaclustering | merging | scaling | masks_folder |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.024929 | 0.284928 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.023377 | 0.000000 | 0.000000 | ... | 0 | 0 | CRC_1_ROI_001.ome.fcs | 7139 | SSA | 64 | 18 | discard | %quantile99.9 | C:/Users/Default/Desktop/Example_IMC/masks/exa... |
| 1 | 0.048936 | 0.038894 | 0.266123 | 0.033602 | 0.000000 | 0.000000 | 0.000000 | 0.302601 | 0.000000 | 0.000000 | ... | 1 | 0 | CRC_1_ROI_001.ome.fcs | 7139 | SSA | 9 | 1 | beta_catenin | %quantile99.9 | C:/Users/Default/Desktop/Example_IMC/masks/exa... |
| 2 | 0.071368 | 0.040151 | 0.208277 | 0.052851 | 0.009086 | 0.000000 | 0.000000 | 0.550454 | 0.249777 | 0.000000 | ... | 2 | 0 | CRC_1_ROI_001.ome.fcs | 7139 | SSA | 4 | 1 | beta_catenin | %quantile99.9 | C:/Users/Default/Desktop/Example_IMC/masks/exa... |
| 3 | 0.091925 | 0.026662 | 0.000000 | 0.019532 | 0.008359 | 0.000000 | 0.000000 | 0.479541 | 0.000000 | 0.000000 | ... | 3 | 0 | CRC_1_ROI_001.ome.fcs | 7139 | SSA | 4 | 1 | beta_catenin | %quantile99.9 | C:/Users/Default/Desktop/Example_IMC/masks/exa... |
| 4 | 0.110583 | 0.042182 | 0.126066 | 0.012851 | 0.005500 | 0.000000 | 0.000000 | 0.505777 | 0.000000 | 0.000000 | ... | 4 | 0 | CRC_1_ROI_001.ome.fcs | 7139 | SSA | 4 | 1 | beta_catenin | %quantile99.9 | C:/Users/Default/Desktop/Example_IMC/masks/exa... |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 36922 | 0.944983 | 0.123140 | 0.000000 | 0.033898 | 0.011610 | 0.000000 | 0.000000 | 0.023377 | 0.088481 | 0.000000 | ... | 36922 | 9 | CRC_3_ROI_004.ome.fcs | 7139 | TA | 53 | 6 | CD32b | %quantile99.9 | C:/Users/Default/Desktop/Example_IMC/masks/exa... |
| 36923 | 0.945010 | 0.046166 | 0.000000 | 0.158551 | 0.000000 | 0.126720 | 0.000000 | 0.016833 | 0.523257 | 0.000000 | ... | 36923 | 9 | CRC_3_ROI_004.ome.fcs | 7139 | TA | 67 | 15 | CD11b | %quantile99.9 | C:/Users/Default/Desktop/Example_IMC/masks/exa... |
| 36924 | 0.945037 | 0.051315 | 0.281774 | 0.026245 | 0.006147 | 0.186344 | 0.410744 | 0.016503 | 0.220021 | 0.000000 | ... | 36924 | 9 | CRC_3_ROI_004.ome.fcs | 7139 | TA | 37 | 13 | p_selectin | %quantile99.9 | C:/Users/Default/Desktop/Example_IMC/masks/exa... |
| 36925 | 0.945064 | 0.036582 | 0.000000 | 0.146609 | 0.010449 | 0.158396 | 0.000000 | 0.074807 | 0.000000 | 0.000000 | ... | 36925 | 9 | CRC_3_ROI_004.ome.fcs | 7139 | TA | 15 | 5 | beta_catenin | %quantile99.9 | C:/Users/Default/Desktop/Example_IMC/masks/exa... |
| 36926 | 0.945091 | 0.102442 | 0.000000 | 0.037356 | 0.000000 | 0.000000 | 0.349168 | 0.028050 | 0.000000 | 0.153938 | ... | 36926 | 9 | CRC_3_ROI_004.ome.fcs | 7139 | TA | 46 | 13 | p_selectin | %quantile99.9 | C:/Users/Default/Desktop/Example_IMC/masks/exa... |
36927 rows × 48 columns
We can also export simple subsets & groups in the data. This example takes only the sample_id’s 1-3, and groups them by unique sample_id, condition, and metaclustering, exporting the mean of each channel in the unique groups. Valid groupby_columns are columns in self.data.obs.
Note that even though the condition column is redundant with the sample_id column (every sample_id has only one condition associated with it), I include it the groupby_columns so that it will be exported into the final CSV. If the grouping was only on sample_id and metaclustering, then the same numbers and groups would be made, but the condition column would not be in the exported file. You could reconstruct which conditions applied to which smaple_ids but that would be a pain.
[34]:
data_table = Analysis_experiment.export_data(filename = "export_clusterings",
subset_columns = ['sample_id'],
subset_types = [[1,2,3]],
groupby_columns = ['sample_id', 'condition', 'metaclustering'],
statistic = 'mean')
[35]:
data_table
[35]:
| sample_id | condition | metaclustering | Object | aSMA | p-selectin | Vimentin | CD14 | CD31 | CD16 | ... | CD3 | HistoneH3 | Beta-Catenin | CD45RO | HLA-DR | DNA1 | DNA2 | Seg1 | Seg2 | Seg3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | SSA | 1 | 0.865785 | 0.074378 | 0.025356 | 0.017434 | 0.003001 | 0.013077 | 0.022812 | ... | 0.045610 | 0.283345 | 0.131373 | 0.048128 | 0.017947 | 0.385994 | 0.451117 | 0.213964 | 0.147877 | 0.520604 |
| 1 | 1 | SSA | 2 | 0.915665 | 0.102705 | 0.040173 | 0.058384 | 0.006305 | 0.045018 | 0.024729 | ... | 0.048352 | 0.261299 | 0.067443 | 0.059923 | 0.036391 | 0.372530 | 0.434350 | 0.194065 | 0.179603 | 0.460786 |
| 2 | 1 | SSA | 3 | 0.959677 | 0.070690 | 0.011369 | 0.054594 | 0.008238 | 0.022306 | 0.023889 | ... | 0.025076 | 0.196373 | 0.043492 | 0.053533 | 0.057812 | 0.317394 | 0.382706 | 0.115750 | 0.149198 | 0.457021 |
| 3 | 1 | SSA | 4 | 0.977852 | 0.070690 | 0.011630 | 0.027843 | 0.004595 | 0.008147 | 0.013884 | ... | 0.025758 | 0.238159 | 0.091262 | 0.050077 | 0.034681 | 0.332750 | 0.400282 | 0.110395 | 0.124404 | 0.494553 |
| 4 | 1 | SSA | 5 | 0.870571 | 0.050497 | 0.034417 | 0.015222 | 0.003037 | 0.024768 | 0.064789 | ... | 0.046896 | 0.248695 | 0.139719 | 0.038718 | 0.017525 | 0.358666 | 0.425989 | 0.200307 | 0.140437 | 0.512571 |
| 5 | 1 | SSA | 6 | 0.875025 | 0.184356 | 0.039828 | 0.075379 | 0.009501 | 0.050006 | 0.035161 | ... | 0.067588 | 0.293444 | 0.056406 | 0.064686 | 0.047366 | 0.410455 | 0.472967 | 0.207826 | 0.205702 | 0.464810 |
| 6 | 1 | SSA | 7 | 0.876094 | 0.085646 | 0.028891 | 0.059378 | 0.008863 | 0.035516 | 0.032904 | ... | 0.277323 | 0.217040 | 0.040908 | 0.219001 | 0.046264 | 0.436142 | 0.497079 | 0.211831 | 0.320624 | 0.467062 |
| 7 | 1 | SSA | 8 | 0.861211 | 0.087000 | 0.033835 | 0.053460 | 0.006863 | 0.044872 | 0.038071 | ... | 0.227391 | 0.211267 | 0.058568 | 0.111790 | 0.033965 | 0.442479 | 0.502679 | 0.228747 | 0.327505 | 0.499285 |
| 8 | 1 | SSA | 9 | 0.868679 | 0.158468 | 0.044848 | 0.083110 | 0.009266 | 0.061833 | 0.028187 | ... | 0.094256 | 0.428219 | 0.087834 | 0.159677 | 0.059686 | 0.434145 | 0.493186 | 0.222735 | 0.203026 | 0.470958 |
| 9 | 1 | SSA | 10 | 0.800928 | 0.160903 | 0.270435 | 0.080830 | 0.946780 | 0.611559 | 0.369436 | ... | 0.142266 | 0.345677 | 0.083248 | 0.087618 | 0.048299 | 0.471945 | 0.533911 | 0.236627 | 0.277152 | 0.495039 |
| 10 | 1 | SSA | 11 | 0.759079 | 0.256014 | 0.691225 | 0.547396 | 0.080627 | 0.275489 | 0.202968 | ... | 0.167079 | 0.774368 | 0.216519 | 0.309961 | 0.263742 | 0.252356 | 0.291196 | 0.518869 | 0.374754 | 0.450053 |
| 11 | 1 | SSA | 12 | 0.898496 | 0.085202 | 0.025791 | 0.073190 | 0.008734 | 0.037380 | 0.044350 | ... | 0.058381 | 0.237365 | 0.041566 | 0.074722 | 0.211548 | 0.395355 | 0.459318 | 0.229219 | 0.242385 | 0.447132 |
| 12 | 1 | SSA | 13 | 0.878019 | 0.196957 | 0.242082 | 0.078784 | 0.010856 | 0.071627 | 0.155004 | ... | 0.060179 | 0.251897 | 0.059014 | 0.055992 | 0.055693 | 0.365483 | 0.425970 | 0.192475 | 0.210316 | 0.463161 |
| 13 | 1 | SSA | 14 | 0.872482 | 0.052233 | 0.029739 | 0.053046 | 0.005611 | 0.033027 | 0.030478 | ... | 0.096869 | 0.232088 | 0.041090 | 0.116821 | 0.030750 | 0.403567 | 0.469290 | 0.156443 | 0.196048 | 0.485151 |
| 14 | 1 | SSA | 15 | 0.910522 | 0.120957 | 0.047836 | 0.168950 | 0.017285 | 0.044665 | 0.066491 | ... | 0.062049 | 0.373564 | 0.079809 | 0.124530 | 0.073701 | 0.325074 | 0.383927 | 0.262137 | 0.234932 | 0.444502 |
| 15 | 1 | SSA | 16 | 0.771315 | 0.130387 | 0.159414 | 0.160508 | 0.022187 | 0.156049 | 0.047173 | ... | 0.117297 | 0.391670 | 0.067346 | 0.156620 | 0.097674 | 0.436580 | 0.497023 | 0.314903 | 0.320316 | 0.509577 |
| 16 | 1 | SSA | 17 | 0.845507 | 0.321836 | 0.200094 | 0.574933 | 0.087907 | 0.228101 | 0.326917 | ... | 0.313117 | 0.708548 | 0.238276 | 0.400131 | 0.363935 | 0.218442 | 0.268865 | 0.489900 | 0.331576 | 0.462635 |
| 17 | 1 | SSA | 18 | 0.894519 | 0.092708 | 0.012839 | 0.083037 | 0.010806 | 0.041233 | 0.034218 | ... | 0.042688 | 0.250569 | 0.053224 | 0.065305 | 0.062110 | 0.365674 | 0.431032 | 0.205344 | 0.199474 | 0.461047 |
| 18 | 1 | SSA | 19 | 0.838765 | 0.140024 | 0.037198 | 0.074417 | 0.024898 | 0.067851 | 0.081239 | ... | 0.081853 | 0.337060 | 0.064907 | 0.090270 | 0.135201 | 0.411853 | 0.474527 | 0.225734 | 0.305539 | 0.483803 |
| 19 | 1 | SSA | 20 | 0.910915 | 0.068276 | 0.017043 | 0.074301 | 0.006615 | 0.371104 | 0.025399 | ... | 0.037137 | 0.201943 | 0.052124 | 0.034573 | 0.039841 | 0.324417 | 0.386707 | 0.169735 | 0.189386 | 0.455983 |
| 20 | 2 | SSA | 1 | 0.770066 | 0.027889 | 0.026358 | 0.015570 | 0.002815 | 0.015640 | 0.023429 | ... | 0.043785 | 0.259839 | 0.234536 | 0.040684 | 0.011449 | 0.307894 | 0.374612 | 0.198068 | 0.104087 | 0.554152 |
| 21 | 2 | SSA | 2 | 0.760722 | 0.085098 | 0.039653 | 0.127851 | 0.009040 | 0.043099 | 0.030125 | ... | 0.064660 | 0.230572 | 0.071956 | 0.050170 | 0.043740 | 0.310411 | 0.374699 | 0.139208 | 0.142620 | 0.486290 |
| 22 | 2 | SSA | 3 | 0.802222 | 0.041321 | 0.011592 | 0.106716 | 0.017482 | 0.029863 | 0.041830 | ... | 0.033655 | 0.176842 | 0.045053 | 0.033081 | 0.068873 | 0.269921 | 0.333150 | 0.145679 | 0.159358 | 0.519068 |
| 23 | 2 | SSA | 4 | 0.808201 | 0.049217 | 0.007414 | 0.047232 | 0.002868 | 0.016926 | 0.015250 | ... | 0.035144 | 0.251698 | 0.139811 | 0.045490 | 0.031271 | 0.297121 | 0.369211 | 0.158220 | 0.098036 | 0.523718 |
| 24 | 2 | SSA | 5 | 0.787283 | 0.038045 | 0.051315 | 0.031699 | 0.003488 | 0.025500 | 0.048054 | ... | 0.052722 | 0.346665 | 0.190545 | 0.054747 | 0.019543 | 0.309155 | 0.375014 | 0.170536 | 0.103971 | 0.556982 |
| 25 | 2 | SSA | 6 | 0.787928 | 0.125570 | 0.037515 | 0.145940 | 0.008465 | 0.068300 | 0.030650 | ... | 0.053471 | 0.253107 | 0.055224 | 0.037798 | 0.028528 | 0.341877 | 0.407420 | 0.149102 | 0.130898 | 0.510290 |
| 26 | 2 | SSA | 7 | 0.780646 | 0.043137 | 0.032107 | 0.145625 | 0.010764 | 0.038030 | 0.028328 | ... | 0.318686 | 0.231618 | 0.047160 | 0.189705 | 0.046319 | 0.376973 | 0.443489 | 0.164515 | 0.160708 | 0.520104 |
| 27 | 2 | SSA | 8 | 0.770166 | 0.039447 | 0.030625 | 0.065281 | 0.004877 | 0.029509 | 0.025068 | ... | 0.215855 | 0.246367 | 0.162810 | 0.081668 | 0.024101 | 0.374783 | 0.442835 | 0.189942 | 0.140396 | 0.541944 |
| 28 | 2 | SSA | 9 | 0.759014 | 0.083365 | 0.040126 | 0.118115 | 0.009402 | 0.033219 | 0.027400 | ... | 0.090810 | 0.496536 | 0.116355 | 0.102807 | 0.058135 | 0.351579 | 0.418795 | 0.156679 | 0.119693 | 0.516885 |
| 29 | 2 | SSA | 10 | 0.679875 | 0.090828 | 0.823963 | 0.088038 | 1.000000 | 1.000000 | 1.000000 | ... | 0.207406 | 0.342896 | 0.110884 | 0.045060 | 0.070129 | 0.251093 | 0.323312 | 0.123847 | 0.123345 | 0.543534 |
| 30 | 2 | SSA | 11 | 0.693364 | 0.079460 | 0.239319 | 0.426811 | 0.027758 | 0.083073 | 0.043655 | ... | 0.243913 | 0.310835 | 0.074094 | 0.121555 | 0.213783 | 0.090613 | 0.110043 | 0.177623 | 0.088009 | 0.610193 |
| 31 | 2 | SSA | 12 | 0.815594 | 0.042185 | 0.038864 | 0.161768 | 0.011774 | 0.034240 | 0.052696 | ... | 0.070145 | 0.305920 | 0.064512 | 0.069767 | 0.283704 | 0.352215 | 0.418272 | 0.159677 | 0.147296 | 0.523148 |
| 32 | 2 | SSA | 13 | 0.769545 | 0.084197 | 0.134850 | 0.094743 | 0.009866 | 0.055775 | 0.097127 | ... | 0.041991 | 0.265642 | 0.062725 | 0.038315 | 0.031650 | 0.296440 | 0.365334 | 0.133081 | 0.137012 | 0.514701 |
| 33 | 2 | SSA | 14 | 0.828270 | 0.036928 | 0.033828 | 0.106970 | 0.005923 | 0.052564 | 0.035368 | ... | 0.173356 | 0.251745 | 0.078301 | 0.165865 | 0.025931 | 0.349370 | 0.413809 | 0.129460 | 0.151433 | 0.498561 |
| 34 | 2 | SSA | 15 | 0.820914 | 0.040070 | 0.024333 | 0.107125 | 0.006153 | 0.038112 | 0.030554 | ... | 0.048882 | 0.240752 | 0.043658 | 0.095366 | 0.032617 | 0.334258 | 0.405108 | 0.142624 | 0.168026 | 0.494451 |
| 35 | 2 | SSA | 16 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 36 | 2 | SSA | 17 | 0.786749 | 0.195875 | 0.073756 | 0.355825 | 0.045720 | 0.166654 | 0.091083 | ... | 0.316234 | 0.459804 | 0.147581 | 0.221732 | 0.234108 | 0.310239 | 0.372899 | 0.244658 | 0.190731 | 0.539323 |
| 37 | 2 | SSA | 18 | 0.809067 | 0.067625 | 0.016847 | 0.087090 | 0.004583 | 0.016386 | 0.034300 | ... | 0.096250 | 0.154822 | 0.062325 | 0.043075 | 0.076257 | 0.286204 | 0.346216 | 0.181306 | 0.162974 | 0.526626 |
| 38 | 2 | SSA | 19 | 0.728577 | 0.064836 | 0.016085 | 0.148577 | 0.027587 | 0.076612 | 0.078885 | ... | 0.054321 | 0.255204 | 0.064972 | 0.077504 | 0.121564 | 0.295055 | 0.354948 | 0.170425 | 0.178421 | 0.506782 |
| 39 | 2 | SSA | 20 | 0.742387 | 0.105129 | 0.025910 | 0.103621 | 0.004866 | 0.308920 | 0.005392 | ... | 0.043897 | 0.294476 | 0.056357 | 0.034492 | 0.011760 | 0.280850 | 0.341293 | 0.142183 | 0.118595 | 0.494294 |
| 40 | 3 | SSA | 1 | 0.691362 | 0.105204 | 0.034400 | 0.020485 | 0.003143 | 0.011375 | 0.025078 | ... | 0.047695 | 0.467860 | 0.185060 | 0.049896 | 0.012597 | 0.583857 | 0.633344 | 0.265905 | 0.195965 | 0.522129 |
| 41 | 3 | SSA | 2 | 0.757446 | 0.084986 | 0.033294 | 0.135766 | 0.009839 | 0.035674 | 0.042023 | ... | 0.032154 | 0.401711 | 0.092319 | 0.085364 | 0.025369 | 0.604144 | 0.645427 | 0.222379 | 0.268864 | 0.529993 |
| 42 | 3 | SSA | 3 | 0.659523 | 0.150777 | 0.048875 | 0.268349 | 0.018654 | 0.045372 | 0.050451 | ... | 0.095732 | 0.441637 | 0.133970 | 0.062568 | 0.079772 | 0.510967 | 0.554842 | 0.228810 | 0.238278 | 0.489170 |
| 43 | 3 | SSA | 4 | 0.589683 | 0.052653 | 0.025571 | 0.050007 | 0.001867 | 0.020231 | 0.041315 | ... | 0.021655 | 0.427770 | 0.149588 | 0.054232 | 0.026181 | 0.478199 | 0.530650 | 0.329187 | 0.307362 | 0.518367 |
| 44 | 3 | SSA | 5 | 0.726861 | 0.081366 | 0.036270 | 0.026873 | 0.004170 | 0.017997 | 0.032282 | ... | 0.066527 | 0.650256 | 0.235419 | 0.103745 | 0.024312 | 0.623326 | 0.667813 | 0.259908 | 0.198067 | 0.506053 |
| 45 | 3 | SSA | 6 | 0.710405 | 0.223482 | 0.057622 | 0.197869 | 0.010339 | 0.046411 | 0.036799 | ... | 0.056645 | 0.432256 | 0.081358 | 0.051028 | 0.030320 | 0.619509 | 0.664577 | 0.241488 | 0.246483 | 0.490393 |
| 46 | 3 | SSA | 7 | 0.701526 | 0.094127 | 0.046473 | 0.176719 | 0.010970 | 0.021248 | 0.029786 | ... | 0.243680 | 0.428351 | 0.076664 | 0.158993 | 0.055119 | 0.670975 | 0.711661 | 0.292337 | 0.384936 | 0.487065 |
| 47 | 3 | SSA | 8 | 0.677641 | 0.080512 | 0.029053 | 0.100205 | 0.006902 | 0.017234 | 0.035878 | ... | 0.165184 | 0.392140 | 0.118579 | 0.059799 | 0.020023 | 0.693366 | 0.730768 | 0.283711 | 0.372900 | 0.514691 |
| 48 | 3 | SSA | 9 | 0.711269 | 0.145901 | 0.061894 | 0.187584 | 0.010645 | 0.034739 | 0.035955 | ... | 0.106569 | 0.732465 | 0.170168 | 0.134451 | 0.056289 | 0.677455 | 0.716425 | 0.257830 | 0.246109 | 0.496213 |
| 49 | 3 | SSA | 10 | 0.595778 | 0.166001 | 0.192837 | 0.166157 | 0.849720 | 0.545545 | 0.283694 | ... | 0.058482 | 0.524313 | 0.106597 | 0.078548 | 0.020970 | 0.612144 | 0.651136 | 0.235119 | 0.286017 | 0.502907 |
| 50 | 3 | SSA | 11 | 0.753605 | 0.080769 | 0.175081 | 0.175813 | 0.012587 | 0.014081 | 0.092221 | ... | 0.103481 | 0.733191 | 0.151853 | 0.106129 | 0.206041 | 0.671061 | 0.697013 | 0.192006 | 0.249490 | 0.476081 |
| 51 | 3 | SSA | 12 | 0.693956 | 0.092945 | 0.047090 | 0.214665 | 0.013782 | 0.041098 | 0.070801 | ... | 0.055360 | 0.378560 | 0.065676 | 0.067719 | 0.255312 | 0.615132 | 0.662737 | 0.279646 | 0.386505 | 0.510440 |
| 52 | 3 | SSA | 13 | 0.700844 | 0.260486 | 0.284698 | 0.129157 | 0.008787 | 0.051744 | 0.079799 | ... | 0.042039 | 0.427028 | 0.099631 | 0.052646 | 0.041674 | 0.574611 | 0.626530 | 0.221062 | 0.218558 | 0.486412 |
| 53 | 3 | SSA | 14 | 0.620118 | 0.125551 | 0.028148 | 0.157172 | 0.008794 | 0.018023 | 0.020690 | ... | 0.163707 | 0.478089 | 0.084407 | 0.178790 | 0.030167 | 0.620972 | 0.660678 | 0.211715 | 0.426042 | 0.467872 |
| 54 | 3 | SSA | 15 | 0.695522 | 0.080543 | 0.026421 | 0.117112 | 0.007183 | 0.018316 | 0.028293 | ... | 0.065198 | 0.370186 | 0.059048 | 0.088871 | 0.031965 | 0.618473 | 0.668787 | 0.235011 | 0.352824 | 0.508148 |
| 55 | 3 | SSA | 16 | 0.795900 | 0.128463 | 0.188387 | 0.308051 | 0.016731 | 0.035597 | 0.039243 | ... | 0.125640 | 0.756220 | 0.170978 | 0.110732 | 0.036047 | 0.652106 | 0.694852 | 0.343496 | 0.458316 | 0.508733 |
| 56 | 3 | SSA | 17 | 0.801507 | 0.202544 | 0.072585 | 0.216260 | 0.013656 | 0.191989 | 0.000000 | ... | 0.100695 | 0.808948 | 0.171756 | 0.143334 | 0.241405 | 0.728448 | 0.752435 | 0.452119 | 0.437904 | 0.512216 |
| 57 | 3 | SSA | 18 | 0.765162 | 0.050208 | 0.079838 | 0.033649 | 0.018962 | 0.000000 | 0.000000 | ... | 0.000000 | 0.284669 | 0.067053 | 0.000000 | 0.000000 | 0.376970 | 0.454928 | 0.152028 | 0.100867 | 0.607456 |
| 58 | 3 | SSA | 19 | 0.696459 | 0.111704 | 0.050789 | 0.192594 | 0.032870 | 0.040026 | 0.092958 | ... | 0.032795 | 0.401165 | 0.058931 | 0.047421 | 0.115280 | 0.602416 | 0.652280 | 0.353200 | 0.412941 | 0.576343 |
| 59 | 3 | SSA | 20 | 0.690052 | 0.055267 | 0.000000 | 0.069626 | 0.004317 | 0.202488 | 0.013607 | ... | 0.019274 | 0.394198 | 0.084834 | 0.026482 | 0.011171 | 0.491401 | 0.555231 | 0.133902 | 0.154720 | 0.479889 |
60 rows × 38 columns
Dimensionality Reductions can also be exported, in case you want to plot them in a different software or customize the plots in Python. Note that dimensionality reduction in PalmettoBUG is typically done on a downsampled subset of the data, and not on the whole dataset, so the original cell number (in the full dataset) is included with this exported file.
[36]:
dimensionality_reduction_export = Analysis_experiment.export_DR(kind = "pca", filename = "PCA")
dimensionality_reduction_export
[36]:
| PC1 | PC2 | cell number from original data | |
|---|---|---|---|
| 0 | 0.004127 | 0.017505 | 1 |
| 1 | 0.013839 | 0.009227 | 2 |
| 2 | -0.000918 | 0.019784 | 4 |
| 3 | 0.006597 | 0.011152 | 5 |
| 4 | 0.026255 | 0.011568 | 6 |
| ... | ... | ... | ... |
| 9983 | 0.006567 | 0.001004 | 36909 |
| 9984 | 0.002115 | -0.002503 | 36910 |
| 9985 | 0.004502 | 0.015096 | 36916 |
| 9986 | 0.002467 | 0.000051 | 36922 |
| 9987 | 0.001537 | 0.001002 | 36923 |
9988 rows × 3 columns
[37]:
## this creates a classy_mask folder with .tiff files for each sample_id/file_name
df = Analysis_experiment.export_clustering_classy_masks(clustering = "merging", identifier = "seed1234")
df
[37]:
| merging | file_name | label | |
|---|---|---|---|
| 0 | discard | CRC_1_ROI_001.ome.fcs | 2 |
| 1 | beta_catenin | CRC_1_ROI_001.ome.fcs | 3 |
| 2 | beta_catenin | CRC_1_ROI_001.ome.fcs | 3 |
| 3 | beta_catenin | CRC_1_ROI_001.ome.fcs | 3 |
| 4 | beta_catenin | CRC_1_ROI_001.ome.fcs | 3 |
| ... | ... | ... | ... |
| 36922 | CD32b | CRC_3_ROI_004.ome.fcs | 4 |
| 36923 | CD11b | CRC_3_ROI_004.ome.fcs | 8 |
| 36924 | p_selectin | CRC_3_ROI_004.ome.fcs | 13 |
| 36925 | beta_catenin | CRC_3_ROI_004.ome.fcs | 3 |
| 36926 | p_selectin | CRC_3_ROI_004.ome.fcs | 13 |
36927 rows × 3 columns
Alternative Clustering methods: Leiden and Pixel Classification
NOTE! The cell that use a pixel classifier’s output depends on the previous execution of the SupervisedClassifier notebook in the pixel classifier tutorials!
[38]:
'''
Alternatively, -- there is UMAP-->leiden clustering based cell labels:
'''
Analysis_experiment.do_leiden_clustering(seed = 0, min_dist = 0.1, resolution = 1)
C:\Users\Default\Desktop\PalmettoBUG\palmettobug\Analysis_functions\Analysis.py:962: FutureWarning: In the future, the default backend for leiden will be igraph instead of leidenalg.
To achieve the future defaults please pass: flavor="igraph" and n_iterations=2. directed must also be False to work with igraph's implementation.
sc.tl.leiden(for_fs,
[38]:
True
[39]:
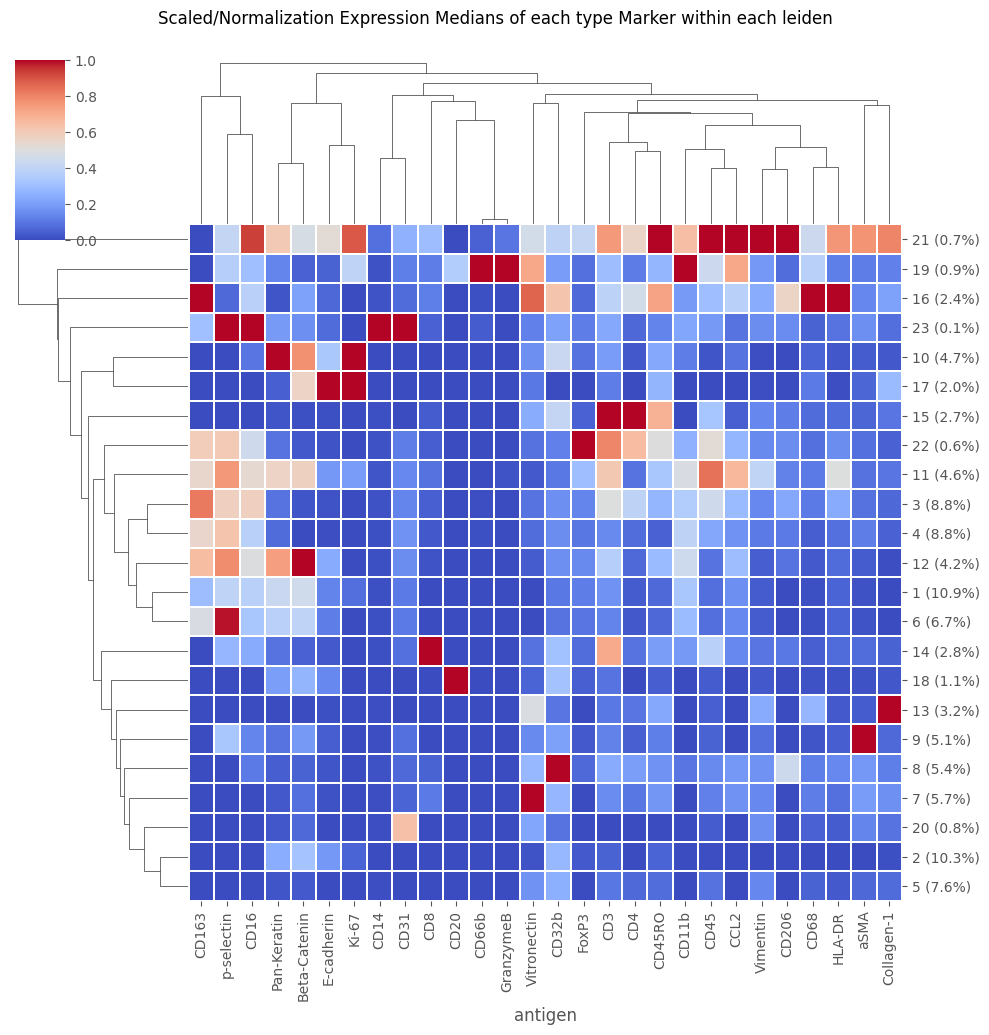
fig = Analysis_experiment.plot_medians_heatmap(filename = "heatmap", marker_class = "type", groupby = "leiden")
fig
[39]:
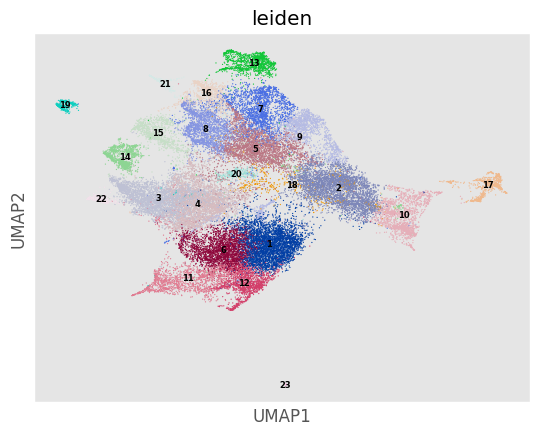
[40]:
'''Doing a leiden clustering automatically also creates a UMAP embedding -- but unlike when using the usual do_UMAP method, the leiden UMAP embeds ALL of the cells in the datasetm
not just a downsampled subset.'''
Analysis_experiment.plot_UMAP(filename = "umap", color_by = 'leiden', palette = None, legend_loc = 'on data', legend_fontsize = 6)
[40]:
[ ]:
Optional: Pixel Classifiers as a means to cluster cells and loading region properties as cell features
[41]:
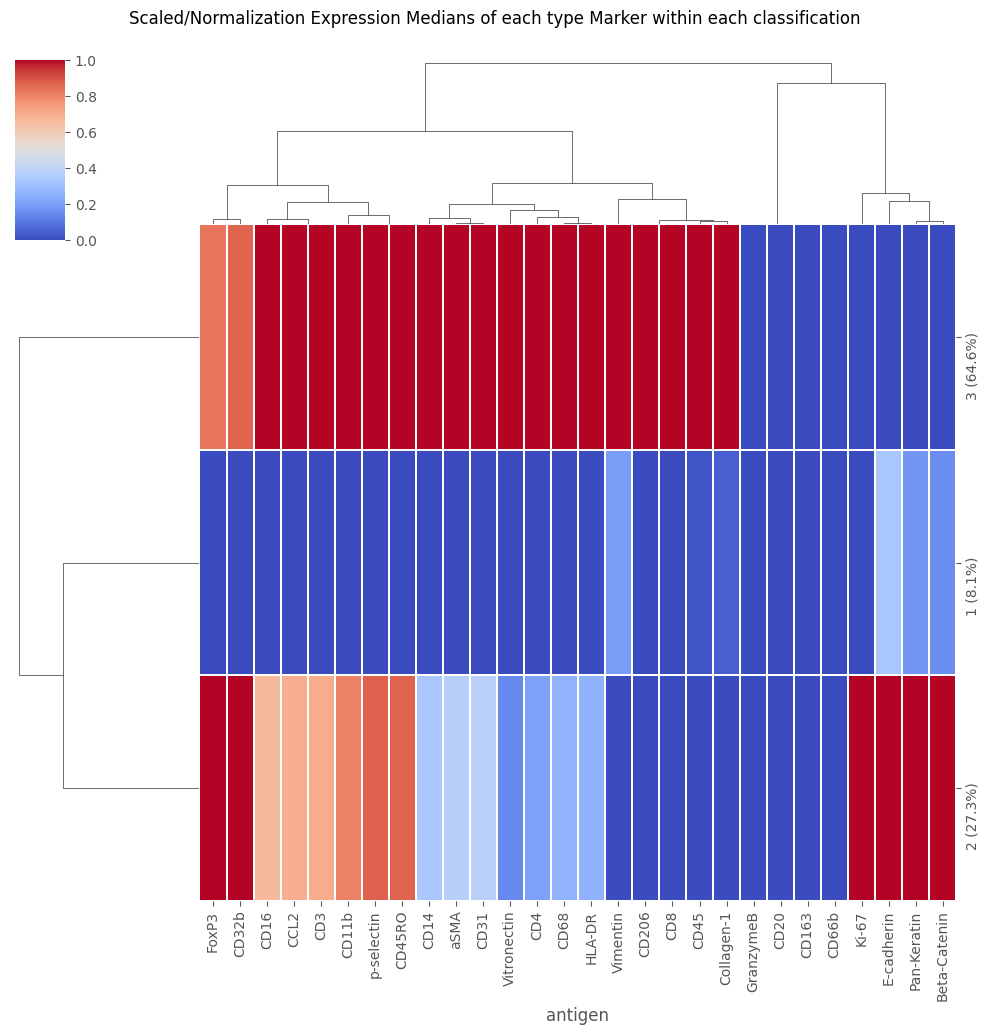
'''
We can load the classy_mask classification as a cell annotation! NOTE: Depends on Supervised Classifier notebook in the pixel classifier tutorials folder!
'''
# load from .csv:
'''The following lines depend on a pixel classifier having been set up & 'classy masks' having been derived from it -- with the output at the indicated path.
GO TO: _______________ note book to see how these classy masks could be generated.
'''
try:
classy_mask_folder = f"{my_computer_path}/Example_IMC/classy_masks/My_classy_deepcell_masks"
cell_classification_paths = [classy_mask_folder + "/" + i for i in os.listdir(classy_mask_folder) if i.find(".csv") != -1]
selected_path = cell_classification_paths[0]
Analysis_experiment.load_classification(cell_classifications = selected_path, column = "labels")
fig = Analysis_experiment.plot_medians_heatmap(filename = "heatmap", marker_class = "type", groupby = "classification")
display(fig)
except FileNotFoundError:
print("Did you first make classy cell masks from a supervised classifier in this folder -- as in the SupervisedClassifier Notebook?")
[42]:
'''
We can also load the region properties calculated for each mask, such as area, perimeter, etc.
and treat these like antigens:
'''
regionprops_panel = Analysis_experiment.load_regionprops()
[43]:
'''
Notice the addition of region properties to the channels -- such as perimeter, area, etc.
'''
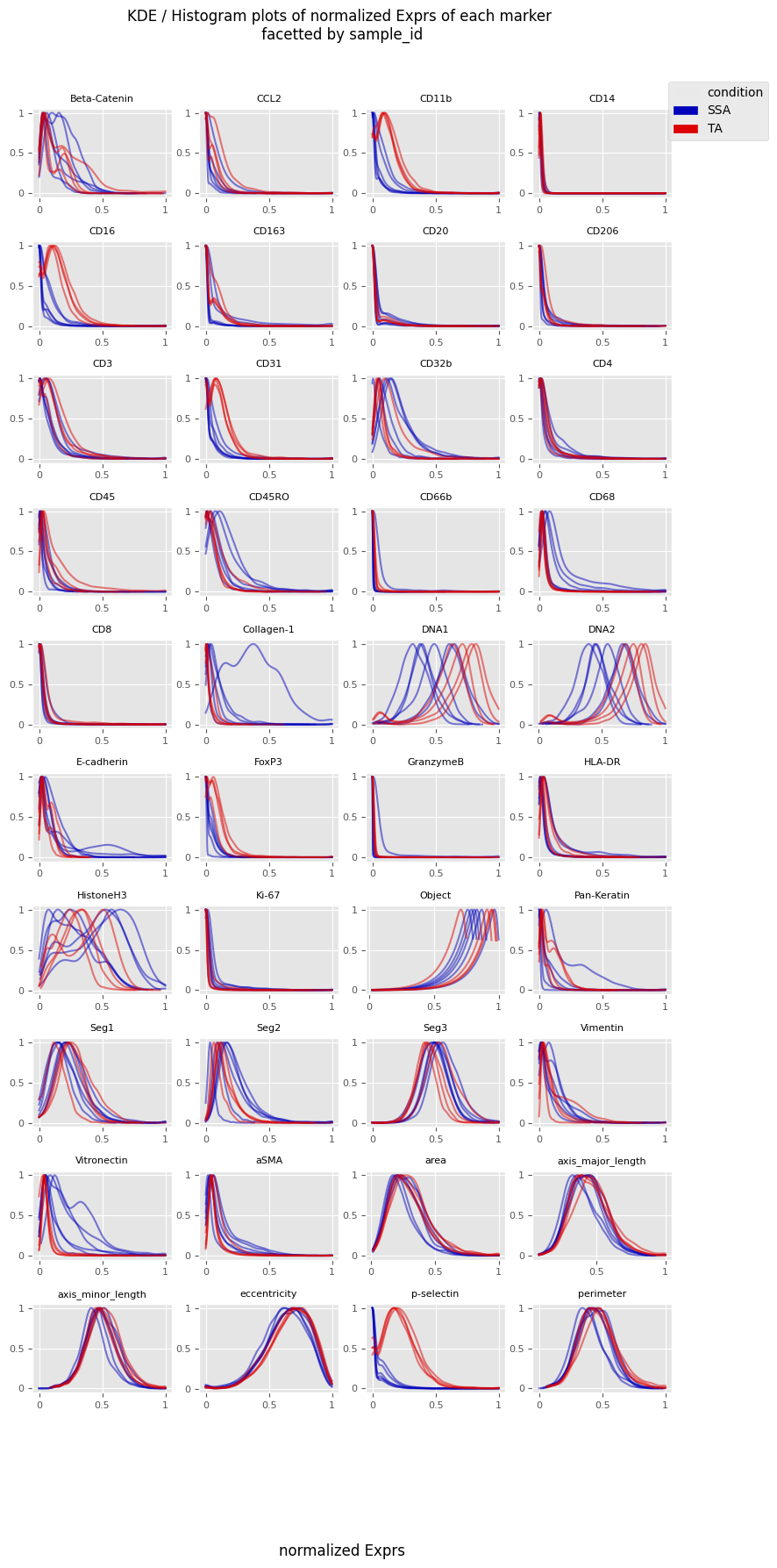
fig = Analysis_experiment.plot_ROI_histograms(filename = "sample_id_histo", color_by = "condition")
fig
[43]:
[ ]: